
Named Entity Extraction in the Tom Regan Papers
January 30, 2019
Born-digital records present a unique opportunity for archivists and researchers to search and explore documents computationally. While a researcher may spend hours, days, or even weeks searching through paper documents to find everywhere a certain name or event is mentioned, a computer can accomplish this task in seconds or minutes - but only when these documents exist in digital form. Many collections from the 20th and 21st centuries contain both physical and digital records; some documents are PDFs or Microsoft Word documents, while others are paper letters and memos that must be digitized before they can be searched computationally.
One of these collections at the NCSU Special Collections Research Center is the Tom Regan Papers (1899-2011), containing materials that span the professional career of one of the most widely-known authorities on animal rights. A recent acquisition for the Tom Regan Papers includes digital files from Regan’s working computer, which he used personally and professionally for many years.

While most operating systems provide the ability to do a basic search across indexed files, there are more robust ways to search and explore records computationally. For example, named entity recognition is the identification of named "real-world" objects, like people, companies, or locations, in collections of text. While a simple search for “apple” may bring up results about fruit, technology, corporations, art, literature, and people, named entity recognition can identify all cases where the Apple company is mentioned. Named entity recognition is useful for searching, but also useful for getting a birds-eye view of a collection of files; with a little bit of code-wrangling, we can run named entity extraction programs to show us the people, places, or organizations that are most frequently mentioned in a group of files.
We did just that with files from Tom Regan’s personal laptop. Using spaCy, a free, open-source library for Natural Language Processing (NLP) in Python, we were able to produce ranked lists of the people most frequently mentioned in the files on Tom Regan’s computer. This process first involved extracting plain text from all the various document types that Tom Regan used: PDFs, Word Documents, PowerPoint slides, .txt files, and others. Then, we had to clean up much of the output that spaCy gave us. Some of the entities erroneously extracted were simply noise, such as “/d03888205s” or “ _18 888” that were extracted from the encoding in documents such as PDFs. Additionally, we applied list filters in Python to be able to produce lists of all people mentioned in the files - Joe, Tom, etc. - or just the entities that had full names - Joe Smith, Tom Regan, etc.
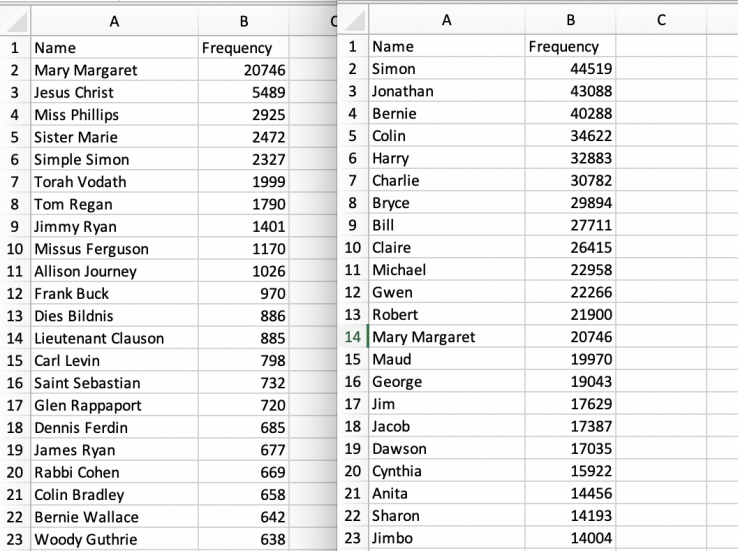
Through this process, we discovered that entities labeled with only a first name are difficult to use in searching or description; it may be interesting that “Joe” is mentioned thousands of times in a collection, but that information is not useful unless we know who Joe is and whether or not there are many Joes being referred to. Other insights are very useful. In the Tom Regan files, we can see that high frequencies of names such as “Jesus Christ” as well as character names mean that Regan used his computer to compose creative writings as well as lectures on philosophy and religion.
Results from this process tell us a little more about what is on Tom Regan’s computer, without the need to go through and read each individual file. Future goals include the integration of named entity extraction into our born-digital processing workflows, so this information can be included in descriptive metadata. These ranked lists are also useful for researchers who want a more holistic view of the collection, or are trying to decide on search terms that will yield the most useful results. As we continue to test these tools on new materials, we will always be looking towards what will be most useful and helpful for our researchers. These applications of technologies to digital archives allow archivists and researchers to deepen our understanding of collections, and to navigate digital collections in more agile ways. Our next steps include conducting additional tests on materials from other collections to see if the process is generally applicable and then determining how to incorporate this work into our digital archiving workflow to create summary descriptive information to include as descriptive metadata. Ultimately, this furthers the department’s goal of supporting the description, discovery, and access of digital archival resources.